
- Reference: Paper Link
- 정리 순서: Abstract → Implementation/Idea → Experiment → Result → Conclusion/Introduction
1. Abstract (간단 정리)
MapReduce(이하, MR)은 큰 데이터 셋을 처리/생성하는 데에 쓰이는 프로그래밍 모델 및 필요한 구현 방법이다.
- Map: key-value(이하, k-v)를 이용해 중간 처리된 k-v 페어를 생성
- Reduce: 중간 처리된 k-v를 k를 기준으로 모으는 작업. 페이퍼에서는 이런 모델로 세상의 많은 작업들을 표현가능하다고 한다.
이런 functional한 방법으로 작성된 프로그램:
- 장점: 자동으로 병렬 그리고 큰 클러스터에서 실행이 가능하다.
실행하는 시스템이 input data의 파티셔닝, 프로그램 실행의 스케쥴링, 장비의 failure 그리고 장비간의 통신을 조율해준다.
이는 프로그래머가 병렬/분산 처리에 대한 이해가 없어도 큰 분산 시스템의 자원을 쉽게 사용할 수 있게 해준다는 것.
이걸 구글은 2004년 이 페이퍼에 “우리는 이미 우리 클러스터에서 매일 수백 테라바이트 데이터 처리하는 데 쓴다~”라고 적어놓았다. (미친 회사)
2. Idea & Implementation
이 논문에서는 “Programming Model”이라는 이름으로 자신들의 아이디어 구상을 설명해 나간다.
대부분의 연산과정은 input k-v pairs를 output k-v pairs로 변환하는 작업이라고 한다. 이걸 MR 라이브러리에서 표현된 두 함수 M, R로 모두 구현할 수 있다.
- Map
- input pair를 받아서 중간 k-v pairs로 변환.
- 동일한 중간 key를 가지면 group → reduce처리됨.
- Reduce
- 중간 key, I와 해당 key에서의 값들을 받음.
- 해당 값들을 더 작은 값의 set으로 merge.
- 하나의 Reduce invocation에서는 보통 하나의 값 혹은 None이 나옴.
- 중간 값이 reduce 함수로 들어가는 건 iteration을 통해
이 방식이 빛을 발하는 때
eg) 메모리에 모든 데이터를 들고 있을 수 없을 정도로 큰 리스트.
2.1 예시
- 문제
- 큰 문서 컬렉션이 있다.
- 해당 문서 컬렉션에서 각 단어의 occurence를 세서 그 결과를 리턴.
- 해결방법 ~~~Pseudo // 참고: MR 라이브러리는 C++로 구현되어 있음.
map(String key, String value): // key: document name // value: document contents for each word w in value: EmitIntermediate(w, “1”);
reduce(String key, Iterator values): // key: a word // values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result)); ~~~
- map 함수는 각 문서의 단어를 for-loop으로 돌면서 (단어, 1)로 중간 k-v pair를 생성
- 중간 k-v pairs는 map함수가 끝나는 시점에 중복되는 키를 기준으로 리스트/어레이로 merge됨.
- reduce함수는 k-v pairs를 하나의 desire하는 값으로 합쳐짐.
- 위 함수에서는 각 vs (리스트) 안에 있는 값들을 sum해 나아감.
- 합쳐진 값을 스트링 형태로 emit함.
- 이러면 해당 key에 대한 occurence count가 나오게 됨.
2.2 Types
- map(k1, v1) → list(k2, v2)
- reduce(k2, list(v2)) → list(v2)
2.3 More Examples
- Distributed Grep
- Count of URL Access Frequency
- Reverse Web-Link Graph
- Term-Vector per Host
- Inverted Index
- Distributed Sort
3. Implementation
페이퍼에서는 사용 환경에 맞게 다양한 구현이 가능하다고 한다. (eg. small shared-memeory machine, large NUMA multi-processor, larger collection of networked machiens) 이 페이퍼에서는 구글이 자신들의 이더넷을 통해 연결시킨 큰 클러스터에서의 환경을 기반으로 설명된다.
환경 설명
- CPU: dual x86 processor
- Mem: 2~4GB
- OS: Linux
- Network: 100Mbps/1Gbps
- Cluster: 수백~수천대의 머신을 연결. (machine failure는 흔한 일.)
- Storage: 각 장비에 직접 연결된 장치 사용. (제일 값싼 방법)
- in-house Distributed File System을 이용해서 각 장비의 데이터를 관리.
- 레플리카를 생성해서 reliability와 availability를 제공. (하드웨어가 unreliable하기 때문)
- How to use: 사용자는 실행할 job들을 scheduling 시스템에 제출한다.
- 각 job은 여러 task들로 구성.
- 각 테스크는 스케쥴러에 의해 클러스터내 여러 장비에 매핑됨.
3.1 실행 전반 (Execution Overview)
- Map
- 사용자가 작성한 작업을 분산환경에서 사용할 머신들이 포크해온다.
- input을 M개의 파일로 쪼개 분산환경에 있는 장비에 뿌려준다.
- 이렇게 쪼개진 파일들은 여러장비에 걸쳐 분산/병렬 처리된다.
- Reduce
- 중간 key 공간을 모을때 R개의 조각으로 파티셔닝한다. (eg. hash(key) mod R)
- 파티셔닝 개수(R)과 파티셔닝 함수는 사용자가 결정한다.
이러한 전반적인 플로우는 아래 그림과 같다.
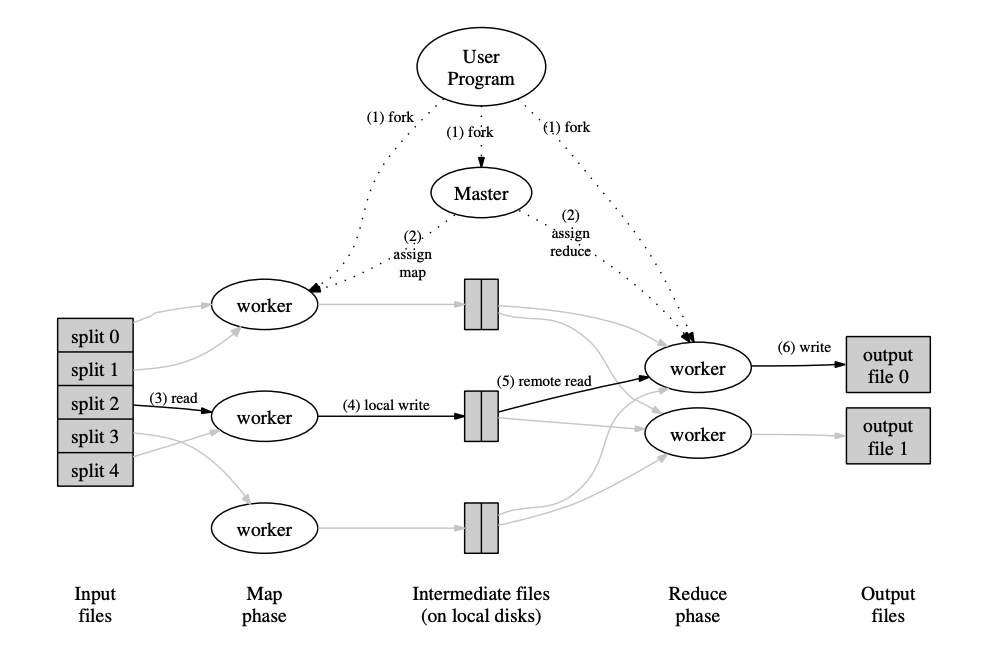
MapReduce Execution Overview
- 사용자 프로그램에 있는 MR라이브러리는 우선, 16~64MB인 M개의 조각으로 나눈다. (이때 조각의 개수는 parameter로 사용자가 결정할 수 있다.) 이제 클러스터에서 사용할 장비로 프로그램을 복사해서 배포하고 실행시킨다.
- 여러 복사 프로그램 중 하나는 마스터의 역할을 한다. 마스터가 다른 워커들에게 작업을 지시한다. M개의 map 작업과 R개의 reduce작업이다. 마스터는 작업을 지시할 때 작업의 종류 (M, R)과 워커의 상태를 보고 워커에게 최적의 작업을 준다.
- map 작업이 할당된 워커는 분할(split)된 input 데이터를 읽어들인다. input data → k-v pairs로 파싱. 파싱된 k-v pairs를 user-defined function (udf, map function)를 이용해 처리한다. udf를 통해 생성된 중간 k-v pairs는 메모리에 버퍼된다.
- 주기적으로 버퍼된 k-v pair는 파티셔닝 함수를 통해 R개의 파티션으로 워커의 로컬 디스크에 작성된다. 저장된 버퍼의 장소는 마스터에 전달된다. 그래야만 reduce 워커들이 해당 위치에서 버퍼를 가져다 처리할 수 있기 때문이다.
- 리듀스 워커는 마스터에서 전달받은 위치(remote: 맵 작업을 한 워커가 저장한 위치)에서 자신 워커의 로컬 장비로 가져온다. 중간 데이터를 모두 읽어들인 다음 중간 key로 정렬한 뒤 동일한 키로 그룹핑된다. 소팅이 필요한 이유는 대부분의 다른 키들이 동일한 리듀스 태스크에 매핑되기 때문. 만약 중간 데이터가 너무 커서 메모리에 들어가지 않으면 외부 소팅(요게 뭘까…?)이 사용된다.
- 리듀스 워커는 소팅된 중간 데이터를 iterate하면서 유니크한 중간 키를 만나면 해당 키와 중간 value를 user’s reduce function에 입력된다. 해당 함수의 아웃풋은 해당 reduce partition을 위한 최종 결과 파일에 append된다.
- 모든 맵 태스크와 리듀스 태스크가 모두 완료되면 마스터는 사용자 프로그램에게 알림을 준다. 사용자가 작성한 MR call은 결과를 code에 return한다.
성공적으로 실행되었다면 MR의 아웃풋은 R개의 아웃풋 파일로 확인할 수 있다. (리듀스 태스크 마다 한개) 사용자는 대체로 이러한 파일을 하나로 합치지는 않는다. 왜냐면 어차피 이 데이터를 또 다른 MR에 사용할 거고 이는 어차피 또 파일을 쪼개야하기 때문.